思路
去到想爬取微博博主的相册,通过 f12 可发现获得数据,我们可以通过正则把图片需要的参数取出来
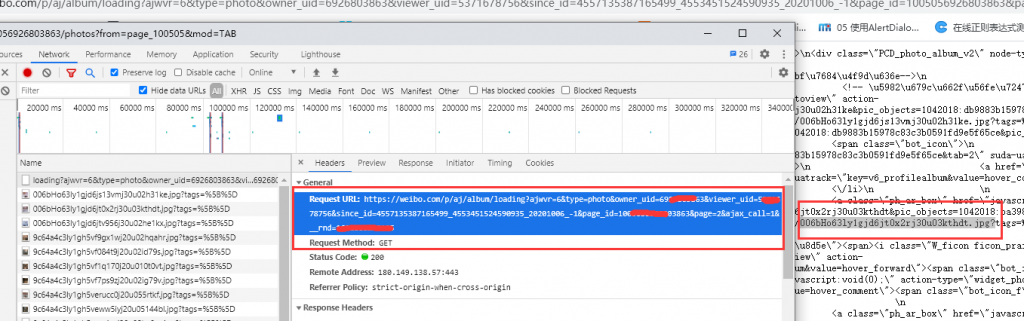
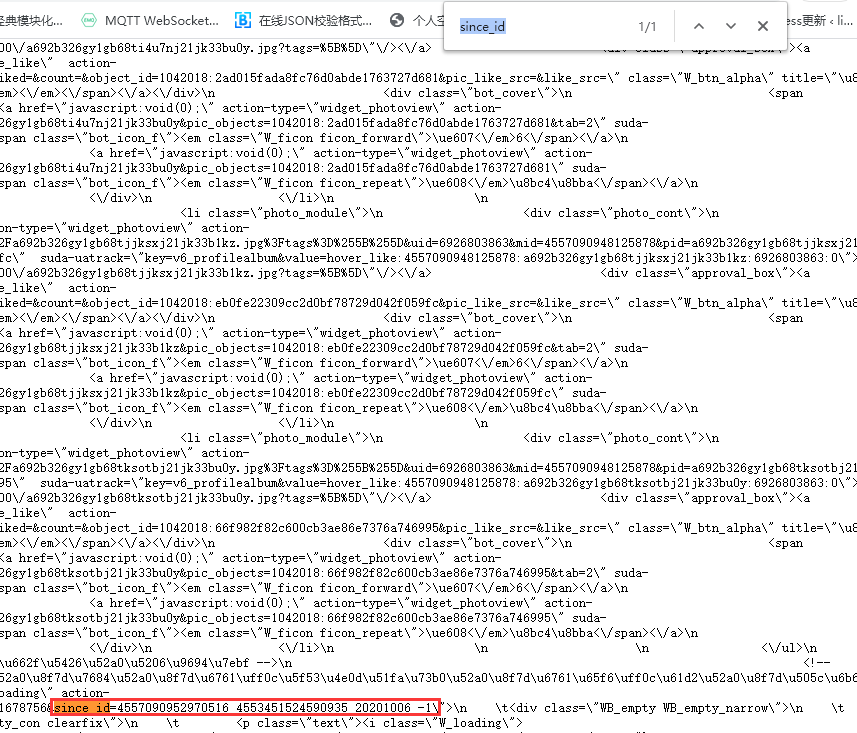
url中的owner_uid、viewer_uid、page_id、__rnd基本是不变的,page是页数,所以只用取since_id就可以了。
代码
import requests
import re
header = {
'Cookie':'填写自己的cookie'
}
owner_uid = '填写f12获取url中的参数'
viewer_uid = '填写f12获取url中的参数 '
page_id = '填写f12获取url中的参数 '
__rnd = '填写f12获取url中的参数 '
i = 1#页数
sore = 1#计数
while(True):
if(i==1):
url_photo_get = 'https://weibo.com/p/aj/album/loading?ajwvr=6&type=photo&owner_uid='+owner_uid+'&viewer_uid='+viewer_uid+'&page_id='+page_id+'&page='+str(i)+'&ajax_call=1&__rnd='+__rnd
html = requests.get(url_photo_get,headers=header)
# 初始主页
html.encoding = 'utf-8'
url_txt = re.findall('thumb300\\\/(.*?)?tags', html.text)#正则初始主页图片的url
since_id = re.findall('&since_id=(.*?)\\\\">',html.text)#正则取since_id
else:
url_photo_get = 'https://weibo.com/p/aj/album/loading?ajwvr=6&type=photo&owner_uid='+owner_uid+'&viewer_uid='+viewer_uid+'&since_id='+since_id[0]+'&page_id='+page_id+'&page='+str(i)+'&ajax_call=1&__rnd='+__rnd
html = requests.get(url_photo_get,headers=header)
html.encoding = 'utf-8'
url_txt = re.findall('thumb300\\\/(.*?)?tags', html.text) # 正则初始主页图片的url
since_id = re.findall('&since_id=(.*?)\\\\">', html.text) # 正则取since_id
while (len(since_id) == 0):
html = requests.get(url_photo_get, headers=header)
html.encoding = 'utf-8'
url_txt = re.findall('thumb300\\\/(.*?)?tags', html.text) # 正则初始主页图片的url
since_id = re.findall('&since_id=(.*?)\\\\">', html.text) # 正则取since_id
if(len(url_txt) != 0):
break
for url in url_txt:
u = re.findall('^(.*?)\?',url)
img_html = requests.get('https://wxt.sinaimg.cn/mw1024/' + u[0])
with open('E:\\photo\\' + str(sore) + '.jpg', 'wb') as f:#保存路径
f.write(img_html.content)
f.close()
print('第'+str(sore)+'张图片:https://wxt.sinaimg.cn/mw1024/' + u[0])
sore += 1
i+=1