准备
(1)可以在pycharm中安装requests库(pycharm中输入pip install requests),因为我我这里是已经安装了。
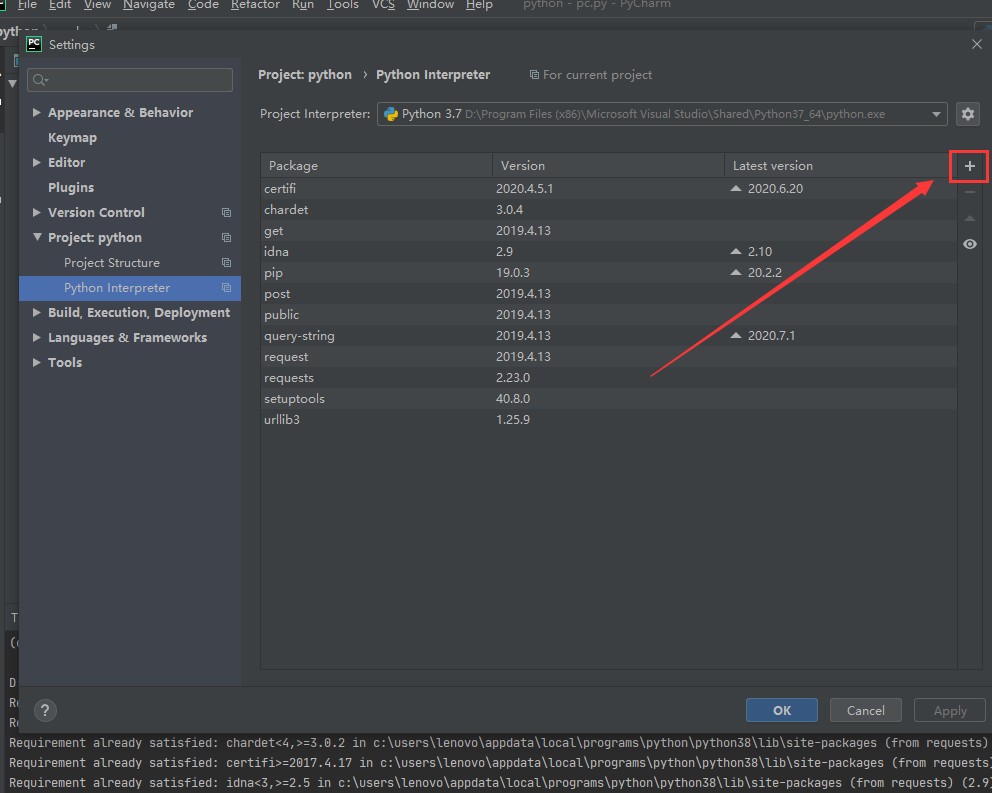
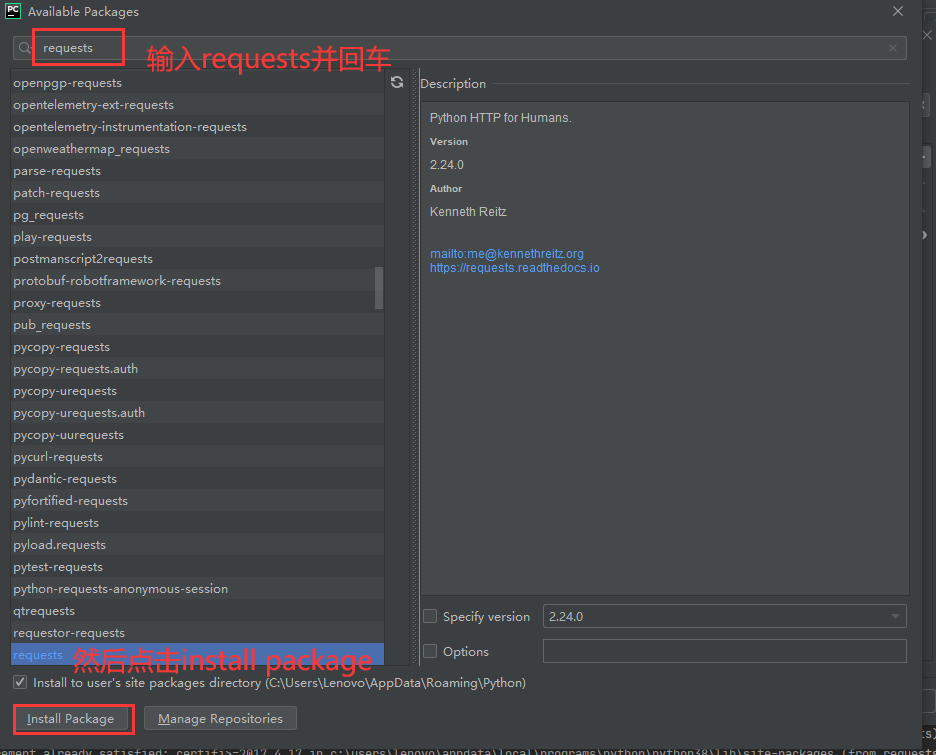
(2)也可以在pycharm中,点击file — settings — project:python — python interpreter
代码
http://pic.netbian.com/index.html所爬取的是这个壁纸网站的图片
import requests
import re
import os
#导入相关包
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3706.400 SLBrowser/10.0.4040.400'}
#配置相关的请求头按需求添加
i=1
j=10
#设置页码
for x in range(1,(j+1)):
#for循环实现翻页获取
if(x==1):
response_one = requests.get("http://pic.netbian.com/index.html",headers=headers)
elif(x!=1):
response_one = requests.get("http://pic.netbian.com/index_"+str(x)+".html", headers=headers)
response_one.encoding = "utf-8"
#发送get请求,返回html 编码为utf-8 一级界面
html_one = response_one.text
#请求返回的html文本赋值给html
urls = re.findall('<a href="/tupian/(.*?).html" ',html_one)
#正则匹配文本
for url in urls:
response_two = requests.get("http://pic.netbian.com/tupian/"+url+".html",headers=headers)
response_two.encoding = "utf-8"
#二级页面
html_two = response_two.text
url_end = re.findall("<img src=\"(.*?)\" data-pic", html_two)
#正则匹配文本
images = requests.get("http://pic.netbian.com"+url_end[0],headers=headers)
#请求图片网址
if not os.path.exists("C:\\Users\\Lenovo\\Desktop\\images"):
os.mkdir("C:\\Users\\Lenovo\\Desktop\\images")
#判断C:\\Users\\Lenovo\\Desktop路径下是否存在images文件夹 没有则创建一个images文件夹
with open("C:\\Users\\Lenovo\\Desktop\\images\\"+str(i)+".jpg","wb") as f:
f.write(images.content)
#以二进制的方式写入 编码为utf-8
i+=1
牛牛牛牛牛牛牛牛牛牛牛牛牛牛